Bir HTML belgesinin omurgası etiketlerdir.
Document Object Model (DOM)’ a göre, her HTML etiketi bir nesnedir. İç içe geçmiş etiketlere, çevreleyen etiketin “alt öğeleri” denir.
Bir etiketin içindeki metin de bir nesnedir…
Tüm bu nesnelere JavaScript kullanılarak erişilebilir.
Bir DOM örneği
Örneğin, bu belge için DOM’u inceleyelim:
<!DOCTYPE HTML>
<html>
<head>
<title>About elks</title>
</head>
<body>
The truth about elks.
</body>
</html>DOM, HTML’i etiketlerin ağaç yapısı olarak temsil eder. Şu şekilde görünür:
Yukarıdaki resimde, eleman düğümlerine tıklayabilirsiniz ve çocukları açılacak / daralacaktır…
Etiketler eleman düğümleri veya sadece eleman olarak adlandırılır. İç içe geçmiş etiketler, çevreleyenlerin alt öğeleri olur. Sonuç olarak bir element ağacımız var: <html> burada köktür, sonra <head> ve <body> gelir bunlar ise html’nin çocuklarıdır vb.
Öğelerin içindeki metin, #text olarak etiketlenmiş metin düğümleri oluşturur. Bir metin düğümü yalnızca bir dize içerir. Alt öğeleri olmayabilir ve her zaman ağacın bir yaprağıdır.
Örneğin, <title> etiketinde "About elks" metni bulunur.
Lütfen metin düğümlerindeki özel karakterlere dikkat edin:
- yeni satır:
↵(Javascript’te bilineni:\n) - boşluk:
␣
Boşluklar ve satır sonları tamamen geçerli karakterlerdir, metin düğümleri oluştup DOM’un bir parçası olurlar.
Dolayısıyla, örneğin yukarıdaki örnekte <head> etiketi, <title> dan önce bazı boşluklar içerir ve bu metin bir “#text” düğümü haline gelir (yalnızca bir satırsonu ve bazı boşluklar içerir).
Yalnızca iki üst düzey istisna vardır:
<head>öncesindeki boşluklar ve satırsonları tarihsel nedenlerden dolayı göz ardı edilir,</body>'den sonra bir şey koyarsak, HTML spesifikasyonu tüm içeriğin<body>içinde olmasını gerektirdiğinden, bu otomatik olarak sonunda “body” nin içine taşınır. Dolayısıyla</body>öğesinden sonra boşluk kalmayabilir…
Diğer durumlarda her şey basittir; eğer belgede boşluklar varsa (tıpkı herhangi bir karakter gibi), o zaman bunlar DOM’da metin düğümleri olurlar ve eğer onları kaldırırsak, o zaman kaybolacaklardır.
Yalnızca boşluk içeren metin düğümleri yoktur:
<!DOCTYPE HTML>
<html><head><title>About elks</title></head><body>The truth about elks.</body></html>DOM ile çalışan tarayıcı araçları (yakında ele alınacaktır) genellikle metnin başında / sonunda boşluklar ve etiketler arasında boş metin düğümleri (satır sonları) göstermez.
Bunun nedeni, esas olarak HTML’yi dekore etmek için kullanılmaları ve gösterilme şeklini etkilememeleridir (çoğu durumda).
Daha fazla DOM resimlerinde, işleri kısa tutmak için bazen ilgisiz oldukları yerlerde bunları çıkarırız.
Otomatik düzeltme
Tarayıcı hatalı biçimlendirilmiş HTML ile karşılaşırsa, DOM oluştururken bunu otomatik olarak düzeltir.
Örneğin, en üstteki etiket her zaman olur. Belgede olmasa bile – DOM’da bulunacak, tarayıcı onu oluşturacaktır. Aynısı
için de geçerlidir .Örnek olarak, HTML dosyası tek bir kelimeyse yani “Hello” gibi bir şey ise , tarayıcı onu içine saracak, gerekli olan
ve kısmını ekleyecek ve DOM şu şekilde olacaktır:DOM oluşturulurken, tarayıcılar belgedeki hataları otomatik olarak işler, etiketleri kapatır vb.
Kapatılmamış etiketlere sahip böyle bir belge:
<p>Hello
<li>Mom
<li>and
<li>Dad…Tarayıcı etiketleri okurken ve eksik kısımları geri yüklerken normal bir DOM haline gelecektir:
<tbody> e sahiptirİlginç “özel durum” tablolardır. DOM şartnamesine göre
'ye sahip olmaları gerekir, ancak HTML metni bunu (resmi olarak) ihmal edebilir. Ardından tarayıcı DOM içinde otomatik olarak oluşturur.HTML gösterimi:
<table id="table"><tr><td>1</td></tr></table>DOM yapısı olarak:
Gördünüz mü ? Aniden <tbody> ortaya çıktı. Sürprizlerden kaçınmak için tablolarla çalışırken bunu aklınızda bulundurmalısınız.
Diğer düğüm türleri
Sayfaya daha fazla etiket ve bir yorum ekleyelim:
<!DOCTYPE HTML>
<html>
<body>
The truth about elks.
<ol>
<li>An elk is a smart</li>
<!-- comment -->
<li>...and cunning animal!</li>
</ol>
</body>
</html>Burada yeni bir ağaç düğümü türü görüyoruz #comment olarak etiketlenmiş bir yorum düğümü.
DOM’a neden bir yorum eklendiğini düşünebiliriz. Yorumlar sayfayı hiçbir şekilde etkilemez. Ancak bir kural vardır – HTML’de bir şey varsa, o zaman da DOM ağacında olmalıdır.
HTML’deki her şey, hatta yorumlar bile DOM’un bir parçası haline gelir.
HTML’nin en başındaki <! DOCTYPE …> yönergesi bile bir DOM düğümüdür. DOM ağacında 'den hemen öncedir. Bu düğüme dokunmayacağız, hatta bu nedenle onu diyagramlar üzerine çizmeyeceğiz, ama oradadır.
Tüm belgeyi temsil eden document nesnesi, resmi olarak bir DOM düğümüdür
12 düğüm tipi vardır. Pratikte genellikle 4 tanesiyle çalışırız:
document– DOM’a “giriş noktasıdır”.- eleman düğümleri – HTML etiketleri, ağaç yapı taşları.
- metin düğümleri – metin içerir.
- yorumlar – bazen bilgileri oraya koyabiliriz, kullanıcıya gösterilmez, ancak JS bunu DOM’dan okuyabilir.
Kendin gör
DOM yapısını gerçek zamanlı görmek için, deneyin Live DOM Viewer. Sadece belgeyi yazın, DOM’u anında gösterecektir
Tarayıcı geliştirici araçlarında görün
DOM’u keşfetmenin bir başka yolu da tarayıcı geliştirici araçlarını kullanmaktır. Aslında, geliştirirken kullandığımız şey bu.
Bunu yapmak için web sayfasını açın elks.html, tarayıcı geliştirici araçlarını açın ve Öğeler sekmesine geçin.
Böyle görünmeli:
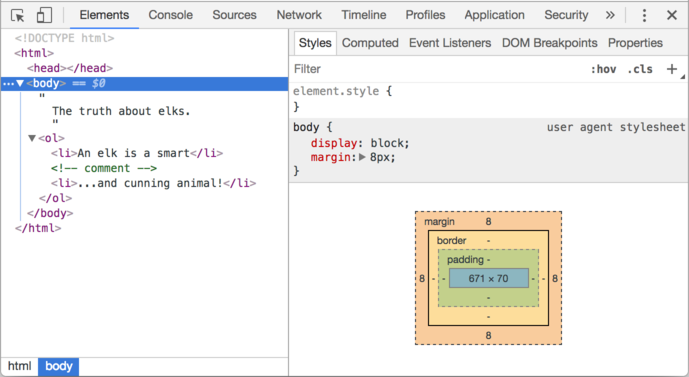
DOM’u görebilir, öğelere tıklayabilir, ayrıntılarını görebilir ve daha fazlasını yapabilirsiniz.
Geliştirici araçlarındaki DOM yapısının basitleştirildiğini lütfen unutmayın. Metin düğümleri sadece metin olarak gösterilir. Ve “boş” (yalnızca boşluk) metin düğümleri de yoktur. Sorun değil, çünkü çoğu zaman eleman düğümleriyle ilgileniyoruz.
Sol üst köşedeki düğmeyi tıklamak , bir fare (veya diğer işaretçi aygıtları) kullanarak web sayfasından bir düğüm seçmeye ve onu “incelemeye” (Öğeler sekmesinde ona kaydırın) izin verir. Bu, büyük bir HTML sayfamız (ve buna karşılık gelen devasa DOM) olduğunda ve içindeki belirli bir öğenin yerini görmek istediğinde harika çalışıyor.
Bunu yapmanın başka bir yolu da bir web sayfasına sağ tıklayıp içerik menüsünde “İncele” yi seçmektir.
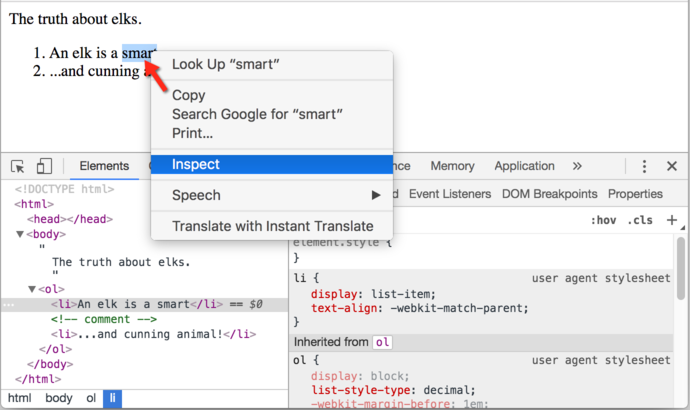
Araçların sağ tarafında aşağıdaki alt sekmeler bulunur:
- Stiller(Styles) – CSS’nin, yerleşik kurallar (gri) dahil olmak üzere belirli öğelere kurallar uygulandığını görebiliriz. Aşağıdaki kutunun boyutları / kenar boşlukları / dolgular dahil hemen hemen her şey yerinde düzenlenebilir.
- Hesaplanmış (Computed) – öğeye uygulanan özellikleri CSS’de görmek için: her özellik için onu veren bir kural görebiliriz (CSS mirası vb. dahil).
- Olay Dinleyicileri (Event Listeners) – DOM öğelerine eklenen olay dinleyicilerini görmek için (serinin sonraki bölümünde bunları ele alacağız). …ve bunun gibi.
Bunları incelemenin en iyi yolu, öğeye tıklamaktır. Değerlerin çoğu yerinde düzenlenebilir.
Konsol ile etkileşim
DOM’u keşfederken, ona JavaScript de uygulamak isteyebiliriz. Örneğin: bir düğüm alın ve sonucu görmek için onu değiştirmek için bir kod çalıştırın. Öğeler sekmesi ve konsol arasında gezinmek için birkaç ipucu.
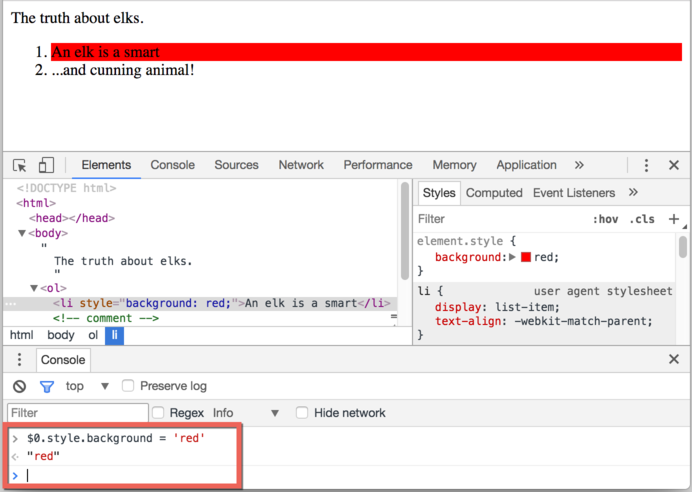
- Öğeler sekmesinde ilk
<li>öğesini seçin. - Esc tuşuna basın – konsolu Elements sekmesinin hemen altında açacaktır.
Artık son seçilen öğe $0 olarak mevcut, önceden seçilen öğe $1 vb.
Onlara komutlar çalıştırabiliriz. Örneğin, $0.style.background = 'red' seçilen liste öğesini şu şekilde kırmızı yapar:
Diğer taraftan, eğer konsoldaysak ve bir DOM düğümünü referans alan bir değişkenimiz varsa, o zaman komutu inspect(node) Elementler bölmesinde görmek için kullanabiliriz.
Ya da bunu konsola çıkarabilir ve document.body kısmını aşağıdaki gibi “yerinde” keşfedebiliriz:
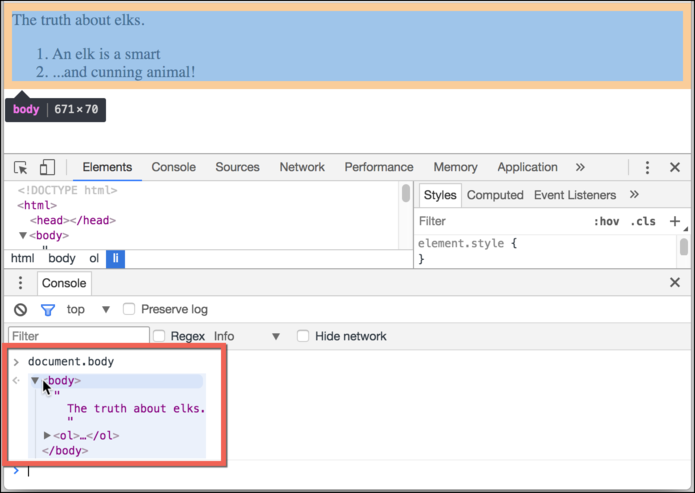
Bu elbette hata ayıklama amaçlıdır. Bir sonraki bölümde DOM’a JavaScript kullanarak erişip değiştireceğiz.
Tarayıcı geliştirici araçları, geliştirmede harika bir yardımcıdır: DOM’u keşfedebilir, bir şeyler deneyebilir ve neyin yanlış gittiğini görebiliriz.
Özet
Bir HTML / XML belgesi tarayıcının içinde DOM ağacı olarak temsil edilir.
- Etiketler eleman düğümleri haline gelir ve yapıyı oluşturur.
- Metin, metin düğümleri haline gelir.
- HTML’deki her şeyin yeri, hatta yorumlar da DOM’da vardır.
DOM’u incelemek ve manuel olarak değiştirmek için geliştirici araçlarını kullanabiliriz. Burada, başlangıç için en çok kullanılan ve önemli eylemlerin temellerini ele aldık. Chrome Geliştirici Araçları hakkında kapsamlı bir dokümantasyon vardır https://developers.google.com/web/tools/chrome-devtools. Bu araçları öğrenmenin en iyi yolu, onlara tıklamak, menüleri okumaktır. Çoğu seçenek tıklamaya açıktır. Daha sonra, onları genel olarak tanıdığınızda, belgeleri okuyun ve gerisini alın.
DOM düğümleri, aralarında gezinmeye, değiştirmeye, sayfada dolaşmaya ve daha pek çok şeye izin veren özelliklere ve yöntemlere sahiptir. Sonraki bölümlerde onlara değineceğiz.
Yorumlar
<code>kullanınız, birkaç satır eklemek için ise<pre>kullanın. Eğer 10 satırdan fazla kod ekleyecekseniz plnkr kullanabilirsiniz)